A Fast Generator for Pseudo-Random Latin Squares
Larry Trammell (retired)
June 4, 2026
version 1.0
Abstract
This report presents an efficient direct generator algorithm — in contrast to an iterative "shuffler" algorithm — for producing pseudo-random Latin Squares. The algorithm can terminate in a bounded number of steps, but for the sake of implementation speed and efficiency, that property is relaxed. The construction proceeds systematically, with each step filling one additional storage cell until algorithm completion. During this process, occasional conflict resolution processes are applied to correct temporary violations of Latin Square properties. The complexity of the expected effort is shown empirically to be approximately O(N2.2). The method is inherently biased; however, a technique to effectively compensate is shown.
Keywords: Latin square, pseudo-random generator, algorithm, covers, random sampling.
Background and prior art
Latin Squares are square layouts of cells arranged in N rows and N columns, where N is a given positive integer parameter establishing the size. Latin Squares have special Latin properties: that each of its N label symbols must appear exactly once in each row and exactly once in each column. A partial Latin Square is a Latin Square layout for which each of the N cell labels appears at most once in any row and at most once in any column, but some of the cells in the layout are empty. A process that applies additional symbol assignments to empty cells in a way that makes a partial Latin Square into a complete one is known as completion. The Latin properties imply a set of Latin constraints for assigning a label to each cell in a partial layout: any label so assigned must not be previously assigned to any other cell in the same row or column. While attempting to construct a Latin Square, label assignments chosen previously for extending a partial Latin Square can result in a cell location for which the Latin constraints cannot be satisfied. This condition is called a conflict. A cell where this occurs is called a conflict cell. While any conflict cell exists, there is no possible assignment of symbols into the remaining empty cells to complete the Latin Square without modifying some of the previously introduced symbol assignments.
If any Latin Square that can exist has an equal chance of being produced by a generator algorithm, the resulting sets of Latin Squares that the generator produces are said to be random. That is a slight misnomer, because the Latin Squares necessarily have internal substructures that are decidedly not random. As used here, and elsewhere, the term "random" describes the process that selects the Latin Square, or statistical properties of a selected set of Latin Squares, not any one square.
Generator algorithms are typically pseudo-random, not perfectly random. Qualitatively, generated results can be considered sufficiently random if a pool of generated results, and another pool of truly random selections, are indistinguishable in any practical sense. If a Latin Square generator produces results that demonstrably favor certain Latin Squares, the generator is said to be biased. The bias is considered "smaller" if its existence is more difficult to detect. Tiny amounts of bias are not necessarily harmful to practical applications.
Completing a partial Latin Square has been an important historical approach for constructing random Latin Squares, and this idea has a long history. Colbourn [1] found that in general the complexity of the Latin square completion problem was NP-complete. Kuhl and Shroeder [2] show that even in the case of one empty row and one missing symbol, the completion problem remains nontrivial. A "divide and conquer" strategy proposed by DeSalvo [3] is also based on the idea of completion, partitioning the problem into an "easy" part and a "hard" part, where the scale of the "hard" part might be small enough to succumb to a brute force attack. However, this approach does not promise to scale up well for large Latin squares.
A widely-known alternative to the completion approach is the shuffling
approach, in which symbol assignments within an initial Latin Square
are adjusted locally, in a manner that temporarily violates but then repairs
the Latin properties within substructures, in the process scrambling
locations where symbols are stored. Obtaining an initial Latin Square
sounds problematic, but actually it is not, because Latin Squares with
well-known structural patterns (like a banded structure) can be calculated
easily. However, naive shuffling operations alone produce insufficient
results. For example, a new Latin Square can be obtained by mapping
the N symbols originally in the Latin Square to a new set of N symbols.
This obfuscation is the mathematical equivalent of printing the Latin Square
using a different type font, which clearly has no effect on mathematical
properties. Another useful but not sufficient idea is to apply
random permutations to rows and columns of an initial Latin Square.
The scrambled Latin Square is more difficult to recognize, but only
(N!·(N-1)!) variations of the original Latin Square
pattern can be produced in this manner, which is a microscopic subset of
all possible Latin Squares. [4] Another well-known
and easily-demonstrated fact is that row permutations and column
permutations do not alter internal cyclic structures of a Latin
Square.
The Jacobson-Matthews algorithm [5] is a more
rigorous shuffler that breaks and later restores 8-cell
substructures within an expanded 3-dimensional representation of a
Latin Square. When properly applied to generate relatively large
Latin Squares, the end result is satisfactory. However, termination
of the scrambling algorithm requires the 8-cell scrambling unit to
satisfy certain structural conditions, and this leads to slightly
favoring Latin Squares where these structures are more prevalent. This
bias is detectable in small Latin Squares but negligible in
Latin Squares of larger size. [6]
Though Jacobson and Matthews showed that the computations have an
O(N3) bound, with some data restructuring
and with reasonable restrictions applied to the number of shuffling "moves,"
the expected effort reduces to O(N2)
[7]. However, a rather large number of operations
is required to statistically assure that most of the initial Latin Square
cells are touched in some manner during the shuffling process, and a
final row-column permutation operation must be applied to scatter any
remaining correlations to the start pattern.
Latin Squares with good randomness properties can be constructed using a recursive depth-first approach: symbols are selected for each cell at random, as long as the selections do not violate Latin constraints. If a conflict condition is reached, and further selections cannot be made without violating Latin constraints, the search backtracks to previous choices, picks an alternative symbol assignment, and then resumes the search as modified. The drawback is that the recursion spans many levels and is highly unpredictable, leading to erratic and sometimes extended run times. Consequently, this idea is practical only for very small Latin Squares.
Circuit substructures of Latin Squares
Using established graph-theoretic terminology [8], a "matching" of any two different symbols within a Latin Square implies a corresponding directed rainbow two-color graph. In these graphs, each node has one of two labels, call these "label 1" and "label 2." Each graph edge has one of two "colors," call these "to 1" and "to 2." Each node connects to exactly two directed edges, one of each color. Each edge that arrives at a node "label 1" has the color "to 1," and each edge that departs from a node with "label 1" has the edge color "to 2." Correspondingly, nodes with label "label 2" have one arriving edge colored "to 2" and one departing edge colored "to 1."
From a Latin Square, pick any "first symbol" and any other "second symbol". Let each of the graph nodes labeled "label 1" be uniquely associated with a row of the Latin Square, at the cell location that contains symbol "first symbol." Similarly, let each of the graph nodes labeled "label 2" be uniquely associated with a column of the Latin Square, at a cell location that contains symbol "second symbol." Let each graph edge colored "to 1" be associated with a path in the Latin Square along a column from a cell containing "second symbol" to a cell containing "first symbol." We know these cells are present; that is the Latin properties. Similarly, let each graph edge colored "to 2" be associated with a path in the Latin Square along a row from a cell containing "first symbol" to a cell containing "second symbol."
Applying the solution demonstrated for Euler's famous "Seven Bridges of Kőnigsberg" problem, [9] the graphs implied by the symbol pairing must exhibit a special structure in which there are only circular paths, along transitions of alternating colors, tracing from node to node along the directed edges until eventually arriving back at the starting node. The corresponding paths in the Latin Square must therefore share the circular properties. We can temporarily disregard all of the other cells within the Latin Square where the various other symbols are stored. The circular paths implied by all of the various symbol pairings define substructures within the overall Latin Square layout.
For example, in Figure 1, the symbols "1" and "3" have been arbitrarily selected as the symbols corresponding to a circular path of current interest. As can be seen readily, starting from any cell with the symbol "1", tracing a path to the symbol "3" in the same row, then tracing a path to the symbol "1" along the column of that cell, then tracing a path to the symbol "3" in that row, and so forth, follows a circular path.
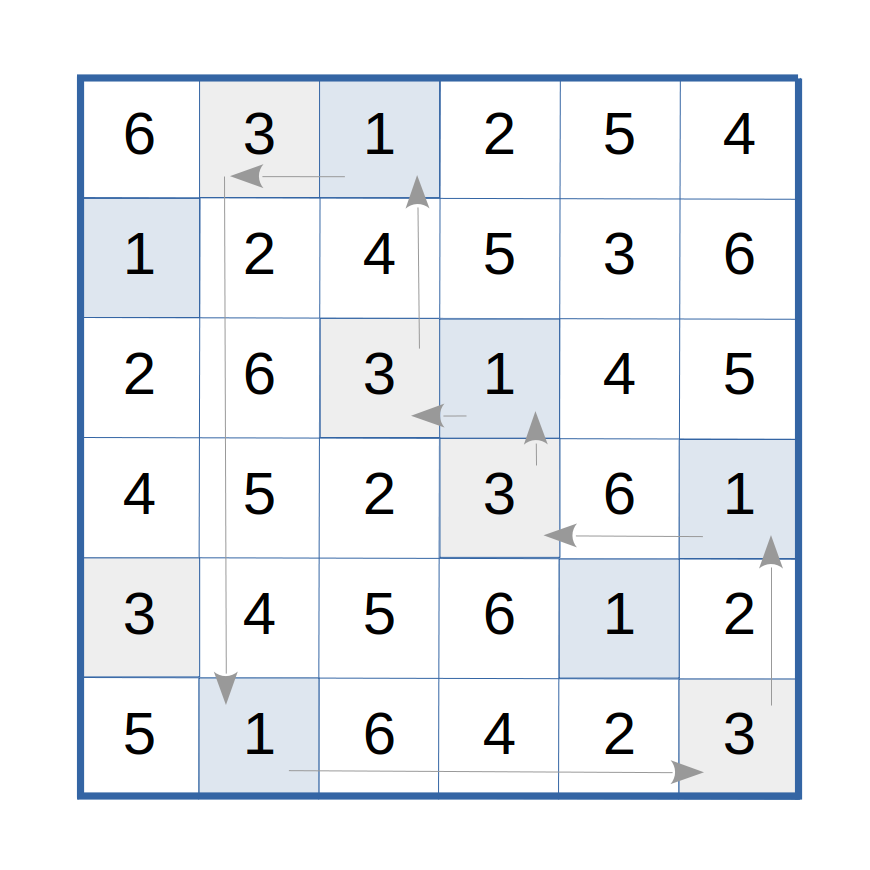
Figure 1: A symbol matching implies a circular path.
A subtlety, however, is that these circular paths do not necessarily visit all of the rows and all of the columns of the Latin Square: the associated two-color graphs are not necessarily connected. For example, in Figure 1, using the symbols "1" and "4" instead of "1" and "3" to start a path in the first row results in a circular path that visits only three of the rows and three of the columns. Another isolated circular path can be found that connects the other three rows and columns.
As a matter of convenient terminology, the circular paths identified in the Latin Squares are called "circuits," and the process of selecting and walking through an implied circular path is called "tracing a circuit." This does not imply the "a circuit" is any kind of new or novel structure.
Covers
Another important kind of substructure of Latin Squares is called
a cover. A cover in a Latin Square of size N x N
is a set of N cells from that Latin Square such that exactly one
one of these cells is located in every row, and exactly one of these
cells is located in every column. This kind of structure is produced by
the classic "Eight Queens" problem often used as a tutorial in an algorithms
course. That problem can be stated as follows:
In the game of chess, a queen is a piece that can attack
any other piece that is present in the same row or same column on a square
chess board with 8 rows and 8 columns. How can you place 8 queens on the
chess board so that no queen can attack any other queen?"
It turns out that there a lots of solutions for this, and the cover approach is a non-recursive way to get one.
Eight Queens solution using covers
Prepare an unordered list of 8 row index numbers, rows 1 through 8
Prepare an unordered list of 8 column index numbers, columns 1 through 8
For queens 1 through 8 :
Pick a row index randomly from the row availability list.
Remove the row from the row availability list.
Pick a column index randomly from the column availability list.
Remove the column from the column availability list.
Place the queen at the row-column location indicated by chosen indices.
End for
Removing from further availability the row and column where a queen is placed further guarantees a kind of "Latin property" so that there is at most one queen in any row or in any column.
The Latin properties of a Latin Square guarantee similar covering properties. Any given symbol must occur exactly one time in every row and exactly one time in every column. The cells containing those N copies of that symbol form a cover for the Latin Square rows and columns in exactly the same sense that the squares with queens form a cover of the chess board in the Eight Queens problem. Because this holds true for any symbol, a Latin Square can always be decomposed into N separate but interleaving covers, with no two covers sharing the same cell. The interleaving covers must exist in every Latin Square that exists. Or working in the reverse direction, if you can identify the interleaving covers, they can be combined to build a Latin Square.
As a historical note, it can also be observed that the classic transversals of a Latin Square examined by Euler [10] are also a kind of cover. A transversal is a cover set of N cells from a Latin Square that additionally has the property that no two cells in the cover contain the same symbol.
The cover approach has some special advantages.
- As seen in the Eight Queens example, covers are relatively easy structures to construct and apply.
- Imposing a cover on a Latin Square does not forces any kind of arbitrary structure that does not exist already in every Latin Square.
- Covers are defined and valid (even if not particularly meaningful!) for Latin Squares as small as size N=1.
The cover method for Latin Squares
The idea is to construct N covers, each one associated with N storage cells of the Latin Square. Do this in a manner such that the covers interleave, so that each cell of the Latin Square is included within exactly one cover. For each cover, assign a unique symbol, and copy this symbol into every cell of the cover. Do this in a "random" manner that does not give any kind of prior preference for which cells are incorporated into which of the interleaved covers.
There is no restriction on the order that rows and columns are considered while constructing the cover. The construction algorithm can proceed one cover at a time, that is, one symbol at a time. Within that cover, cells not already used by other defined covers can be selected from rows in an arbitrary manner, and a lexical row order from 1 to N can be applied to do this. When selecting an unoccupied cell from a row, that cell must be in a column that has not previously been selected during the construction of the current cover.
Supporting data structures
A supplementary data structure facilitates cover construction. One instance is used to manage assignments of symbols within rows, and a parallel instance is used to manage assignments of symbols within columns.
A sub-problem faced by cover-building methods is: "find a cell within the given partial Latin Square row such that the cell is not currently assigned any symbol." While this is not difficult, it usually requires a sequential scan through the existing contents of the row seeking a suitable cell. The extra scan and the algorithm complexity resulting from it can be eliminated by maintaining an "availability index" partitioned into two parts, the locations that have been assigned a symbol and the locations that have not. This reduces complexity at the expense of additional constant overhead for every access of a cell in the Latin Square storage.
A related sub-problem that occurs repeatedly: "find a cell within a partial Latin Square row where a specified symbol is located." Partitioning features can determine whether the symbol is present or not, but can provide no information about where to find a symbol. An array of "reverse lookup" indices can provide this information. Given the row index and the identity of the symbol, the reverse index reports the column location within the row where that symbol is present. Similarly, a "reverse lookup" for columns can report where in each column a specified symbol is located.
These two forms of indexing are incorporated into a single class called a "split-list" (from the way it is partitioned to distinguish locations that do and don't have assigned symbols). Using one of these structure to manage columns and one to manage rows adds a requirement of 4 N2 storage locations.
Using the indexing structures to manage most of the low-level storage administration details, here is a high-level overview of the algorithm for the Cover Method for constructing Latin Squares.
Latin Square by the Cover Method
Initialize the split list indexing structures for rows and columns.
For sym = 1 to N
For row = 1 to N
Locate the column col of an empty cell in the row
If col is found successful,
Cross reference sym in the row indexing structure
Cross reference sym in the col indexing structure
Store symbol sym into the Latin Square at location (row, col)
Otherwise
Perform a conflict resolution for the row
End if
End for
End for
While this seems straightforward, there are serious problems that must be addressed regarding the issue of conflict resolution.
The problem of conflicts
As the number of completed covers grows, fewer choices remain for cells to contribute to additional covers. It is possible that all unoccupied cells in the row are made unavailable in this manner; if that occurs, the construction of the current cover cannot continue. When this kind of conflict occurs, it must be remedied immediately so that the current cover can be completed, otherwise the entire Latin Square construction process fails.
Figure 2 illustrates a conflict. It can be observed that, to this point, there are no violations of the Latin conditions, and covers are successfully constructed for symbols 1, 2, and 3. However, during the construction of a cover for symbol 4, a problem arises in row 6.
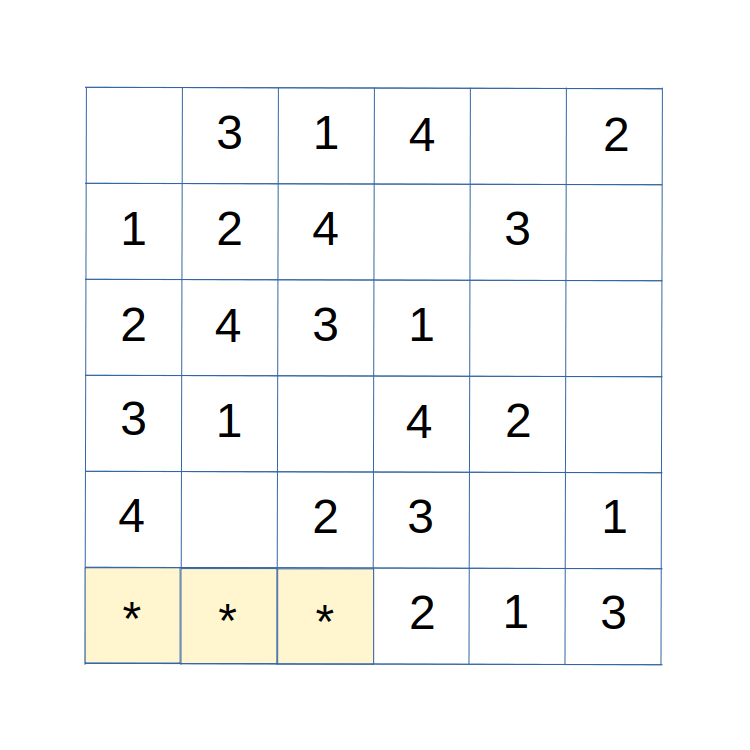
Figure 2: A conflict exists in row 6.
In row 6, there are three empty cells. An empty cell somewhere in row 6 must be included to complete a cover for symbol 4. However, it can be seen that all three of the empty cells already have a symbol 4 present in the column, hence none of the three cells can be assigned a symbol 4 without violating the Latin conditions. There is the conflict. A resolution operation must remove the conflict by modifying some of the earlier label assignment choices.
Two heuristics are provided for removing the conflict.
Conflict resolution by the "split cell" method
For the Latin Square illustrated in Figure 2, we can see that there is an open cell in column 3 of the current row 6 where a conflict is observed, preventing the assignment of a copy of symbol 4 to any cell. Because there is a conflict, we know that the current symbol 4 is present somewhere in column 3. Find the row where that happens. In this case, a copy of symbol 4 is located in row 2. The "split cell" method can be applied if there is an empty cell in that row 2 that happens to be in a column without any copies of current symbol 4 present. In this case, we can see that column 6 satisfies that condition; the cell at row 2 column 6 is empty, while symbol 4 is not currently present in column 6. The conditions for applying the "split cell" resolution are satisfied.
So now to implement the "split cell" operation, the symbol 4 currently located in row 2 at column 3 is removed from that cell and "split" into two copies. One copy is moved down to the column to the vacant location in row 6. The other copy is moved across the row to the vacant cell in column 6. This process is illustrated in Figure 3.
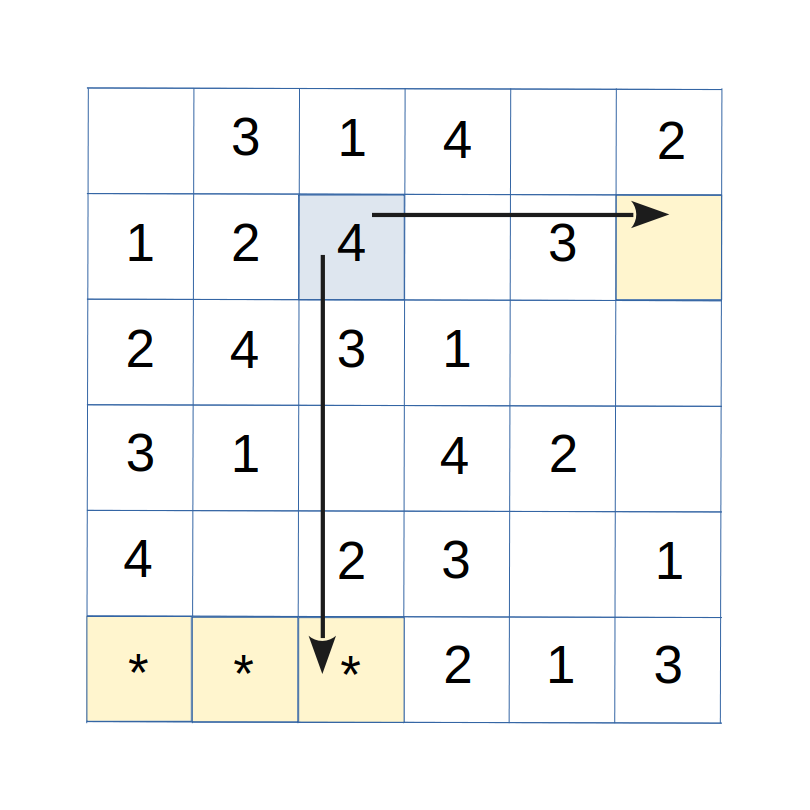
Figure 3: The split-cell heuristic resolves the row 6 conflict.
You can verify that after this operation:
- The current row 6 of the cover now has a valid cell assignment.
- There are no violations any Latin Constraints in the layout.
- The conflict is resolved.
The "split cell" approach is highly desirable because it does not touch any of the covers previously constructed, and it affects a minimal number of cells in the current construction. Most conflicts are quickly eliminated this way.
However, there is no guarantee that it will work all of the time. When it happens that it is not possible to apply the "split cell" operation at any cell in the current conflict row, some other method must be applied.
Conflict resolution by the "circuit alternation" method
If any circuit has been identified, it can be observed that within the cells of that circuit, after toggling the symbol assignments so that all of the cells that originally had "symbol 1" are reassigned "symbol 2," and all of the cells that originally had "symbol 2" are reassigned "symbol 1," no Latin conditions are violated. We can call this operation a "circuit alternation."
A circuit alternation operation
Let sym be the symbol of the cover under construction.
Call the row where the conflict is found Row 1.
Pick any one of the open cells in Row 1.
Call this the current cell, in column Col 1.
Find a cell in Col1 that currently has symbol sym.
Repeat
If THERE IS NO SUCH CELL,
Store sym in the cell at location Row 1, Col 1.
Terminate the algorithm.
Let the row of the found cell be Row 2.
Clear the cell at Row 2, Col 1.
For all of the other open cells remaining in Row 2
Randomly select one of these cells.
Find a cell in Row 2 that is not in a column where sym is stored.
If such a cell exists
Pick any other open cell in Row 2.
Let the column of this cell be Col 2.
Store sym in the cell at location Row1, Col1.
Shift the current location:
Row1 = Row2
Col1 = Col2
Suppose that at each step when the above algorithm performs a "clear
the cell" operation, it stores a symbol X in the
cell. If you look through the sequence of rows and columns at the
pattern formed by the symbols sym and X, you
can observe that the cells that lie along this path form a circuit; and
since this circuit always results in a closed loop, the algorithm must
terminate in N steps or less.
These facts lead to the important result:
The conflict resolution process of alternation along a circuit
will always terminate in less than N steps, with the
result of eliminating the conflict and filling one of the cells
in the row where a conflict had previously existed.
It can be noted that the temporary X symbols play
no active role in the unfolding of the algorithm. They merely guarantee
that columns can be visited at most one time. However, there is a cost
for that extra layer of assurance, roughly doubling the computational
cost of an alternation operation. Making sure that the circuit trace
never reverses its direction to back up along the path where it just
arrived has almost the same effect, but there is a different
subtle cost. The theoretical guarantee of completion in a finite
number of steps is lost.
The problem of bias
The Method of Covers chooses cells to be included in each cover at random. This strongly suggests that the Latin Squares so constructed will be random. We will now demonstrate why this is not true.
Consider the very simple case of a 4x4 Latin Square. We can observe that if we have any Latin Square, any square obtained by a random permutation of rows and columns will also be a Latin Square. We can choose the column permutation that happens to position the labels 1, 2, 3, and 4 in that order in the first row. The circuit substructures are preserved by the permutations, so these operations do not change the numbers or sizes of circuits present.
In an almost identical manner, we know that for some permutation of rows not including the first, the symbols 2, 3, and 4 can be made to appear in the first column in that order. Again, these permutations preserve the circular substructures.
This leaves us with what is called a "reduced Latin Square" as illustrated in the first Latin Square of Figure 4.
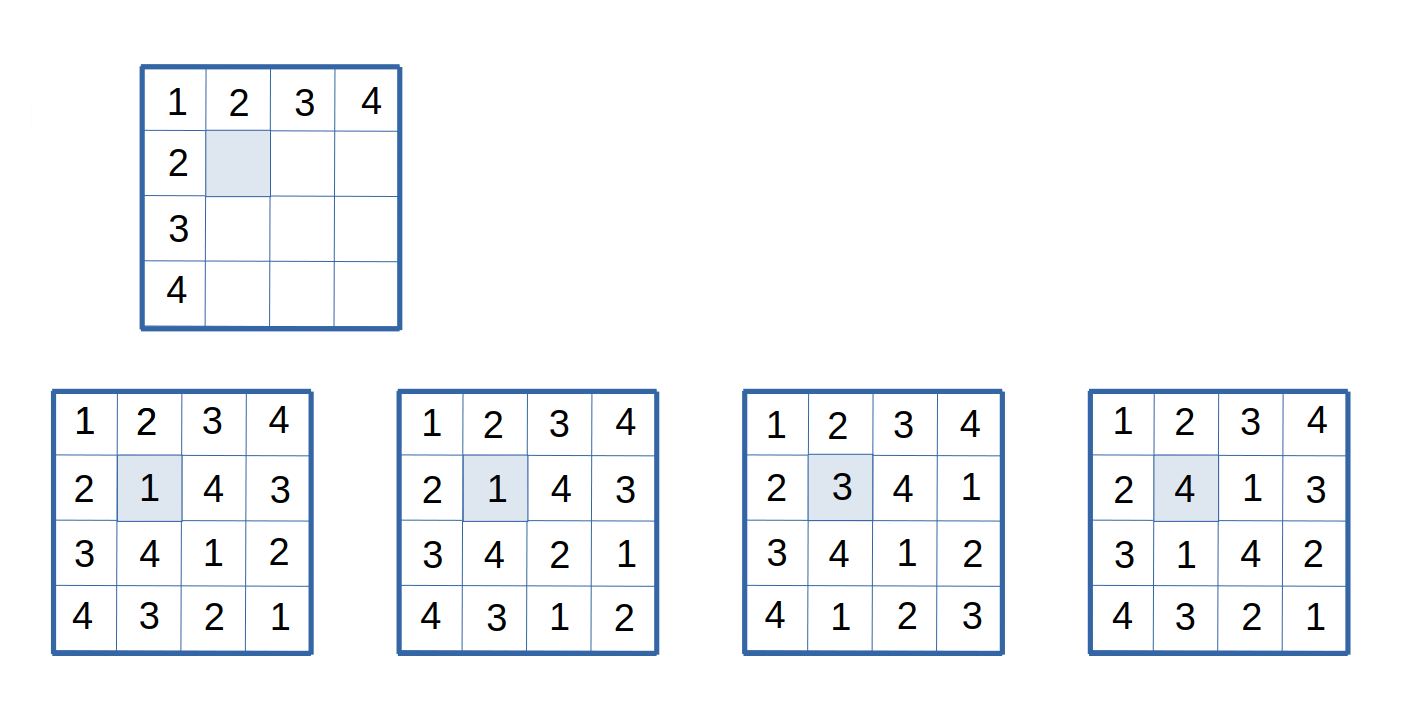
Figure 4: All possible substructures for completing a 4x4 Latin Square.
Starting from the reduced Latin Square, the remaining Latin Squares in Figure 4 show all the possible ways of completing to form a full Latin Square. The tinted cell cannot be assigned a symbol 2, because that symbol happens to be already present in both the row and column. That leaves symbols 1, 3, and 4 as feasible candidates. By assigning one of the candidate symbols, and then applying the Latin constraints repeatedly, we obtain all of the possible completions, as shown in the figure.
But if we now look at those four possibilities, we see that two of them require assignment of the symbol 1 to the tinted square; the others involve assignment of the symbol 3 or the symbol 4. Clearly, if we choose among the symbols 1, 3, and 4 uniformly at random, the symbol 1 will be chosen 1 out of 3 times. But if all possible Latin Squares are selected with equal probability, the tinted cell would be assigned symbol 1 for 2 out of 4 times.
Establishing the non-uniform probabilities for correctly selecting from among the available symbols without bias is not a problem for the size N=4 case, but there is no theory available to predict more generally what the correct distribution must be for other sizes of Latin Squares. That leaves only two options.
- Develop and apply the needed general theory. No small feat.
- Select cells for covers uniformly at random and find a way to deal with the inevitable biases that occur.
We will now present a method, based on the circuit structures implied by symbol matching, to apply the second strategy above, compensating for (but not completely eliminating) the bias damage.
Bias compensation by circuit toggling
Pick the start row of the biased partial Latin Square randomly.
Pick as the first symbol the sym used by the current cover.
Pick as the second symbol any other symbol present in the start row.
Trace the circuit implied by the pair of symbols.
After visiting each cell,
Replace the first symbol by the second symbol
OR
Replace the second symbol by the first symbol
We already know that this operation does not violate any Latin constraints. But does it have any useful effect? As it turns out, yes, as illustrated in Figure 5.
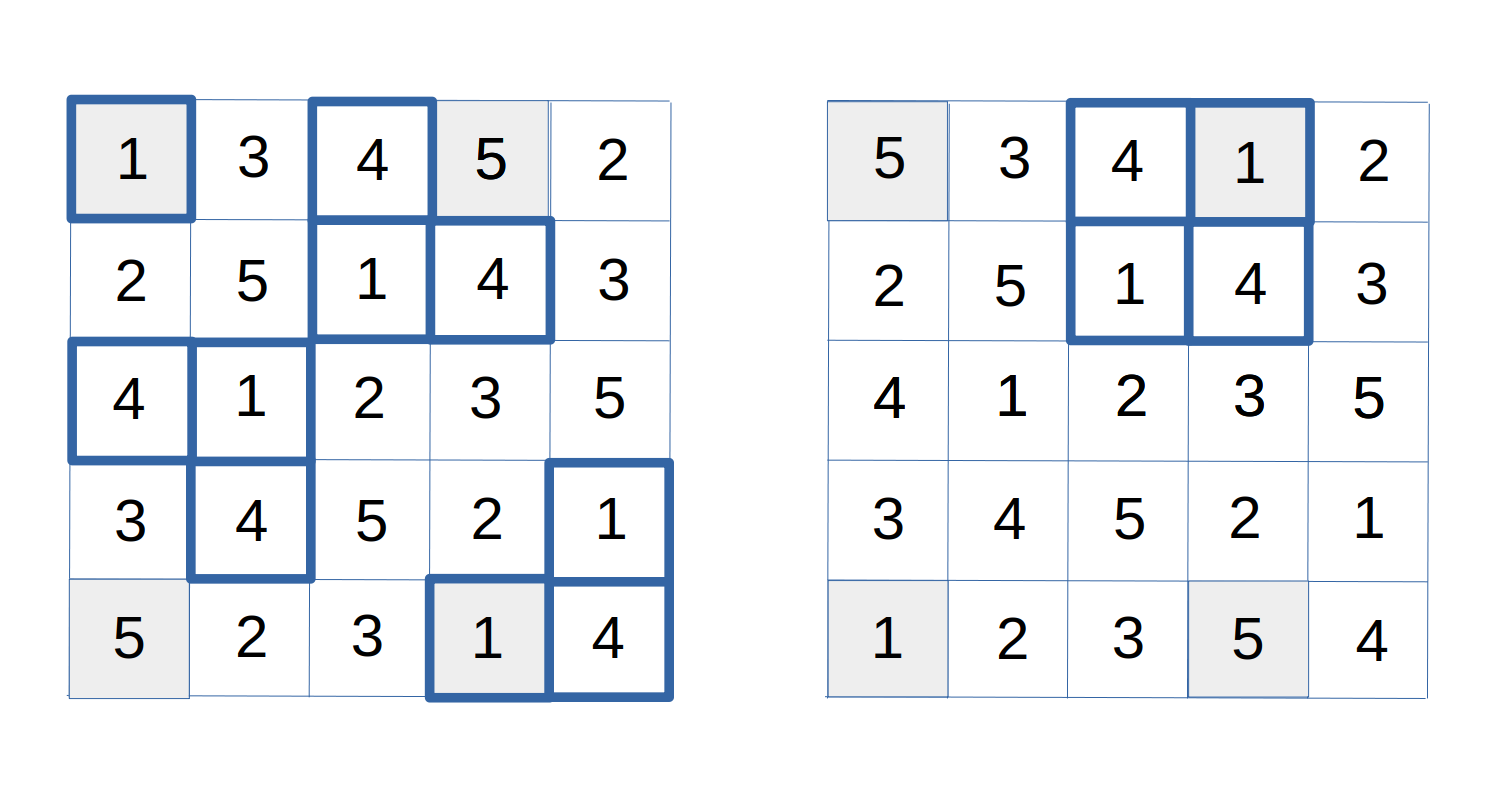
Figure 5: The side effects of a circuit toggle operation.
In the Latin Square at the left of figure 5, two circuits are identified. The circuit implied by symbols 1 and 5 is indicated by shading the cells along that circuit. The circuit for symbols 1 and 4 is indicated by cells with thick borders.
A label toggling operation is then applied to the 1-5 circuit, transforming the Latin Square shown on the left to the one shown on the right. This happened to change only 4 cells, though it might have altered as many as 2·N. We can verify that the Latin properties are not violated, and in fact, the circuit of the 1-5 symbols has the same cell structure as before. However, the structure of the circuit for the 1-4 cells is completely different. Instead of a circuit touching N rows and N columns, that modified circuit now involves only two rows and two columns.
To apply this idea, a circuit toggling operation is applied after the construction of each cover (except for the first, which does not have the two different symbols necessary to define a circuit).
To see whether this is beneficial, we will apply a screening test for Latin Square bias [6] to a large pool of generated Latin Squares. It was shown that the number of circuits of maximal length has a very specific distribution in collections Latin Squares that are truly random. The Method of Covers is used to generate the pool of Latin Squares, from which 500000 circuits are randomly sampled and tested.
Here are the results of the experiment.
250000 Latin Squares of size 4 500000 circuits sampled and tested No circuit toggle operations applied Maximal circuits encountered: 286884 Maximal circuits expected: 250000 Circuit toggle operations applied once per cover 500000 Latin Squares of size 4 Maximal circuits encountered: 261930 Maximal circuits expected: 250000 Circuit toggle operations applied twice per cover 500000 Latin Squares of size 4 Maximal circuits encountered: 254212 Maximal circuits expected: 250000
A bias is clearly present, because the number of maximal circuits is higher than what we know should be present in truly randomly-selected 4x4 Latin Squares. We can also observe that the more times the circuit toggle operations are applied, the more closely the actual distribution conforms to the theoretical one.
Table 1 shows the results of applying the testing to Latin Squares of varying sizes, using the Method of Covers generator with two randomly selected alternation passes per cover. The results of the sampling are then compared to the reference probability values [6] for truly random Latin Square selections. Table 1 displays the testing results. Also included are corresponding probabilities from similar testing applied to the established Jacobson-Matthews scrambler algorithm (when those results are available).
Table 1 - Probability of encountering maximal circuits
in Latin Squares generated by Cover Method
Size Number of Probability J-M Reference
samples max circuit comparison Probability
4 10000 .508 .500
6 10000 .437 .451 .429
8 20000 .341 .344 .340
10 19800 .273 .274 .272
12 20000 .228 .227 .227
14 25000 .195 .194
16 40000 .171 .170
18 40000 .151 .151
20 50000 .136 .136
Small Latin Squares exhibit a detectable small bias, and this is also true for Latin Squares produced by the Jacobson-Matthews scrambler. For sizes N=10 or above, this sampling experiment was not rigorous enough to detect differences between the two methods and the theoretical reference.
It appears worthwhile to apply the two alternation operations per cover, to achieve the tabulated results shown in Table 1 with quite good bias performance. If bias is not a significant practical concern, however, one or both of the circuit alternation passes could be eliminated, so that results are produced faster.
Algorithm performance
To access all of the cells from the Latin Square storage and
store any kind of content into them would require
N2 operations. This establishes a
minimum baseline complexity O(N2).
From there, two kinds of effort must be accounted for.
- Effort that modifies storage.
- Effort that tests stored values without modification.
If either kind of effort grows relatively faster than
N2, that will determine the ultimate
complexity order of the algorithm.
Effort expended to modify storage
To quantify the effort that involves storage changes, the algorithm is instrumented to count as one unit of effort any operation that modifies a cell of Latin Square storage (including with any associated indexing overhead). Two bias compensation passes per cover are included within the effort tallies. Figure 6 shows observed counts over pools of 2000 generated Latin Squares of each size.
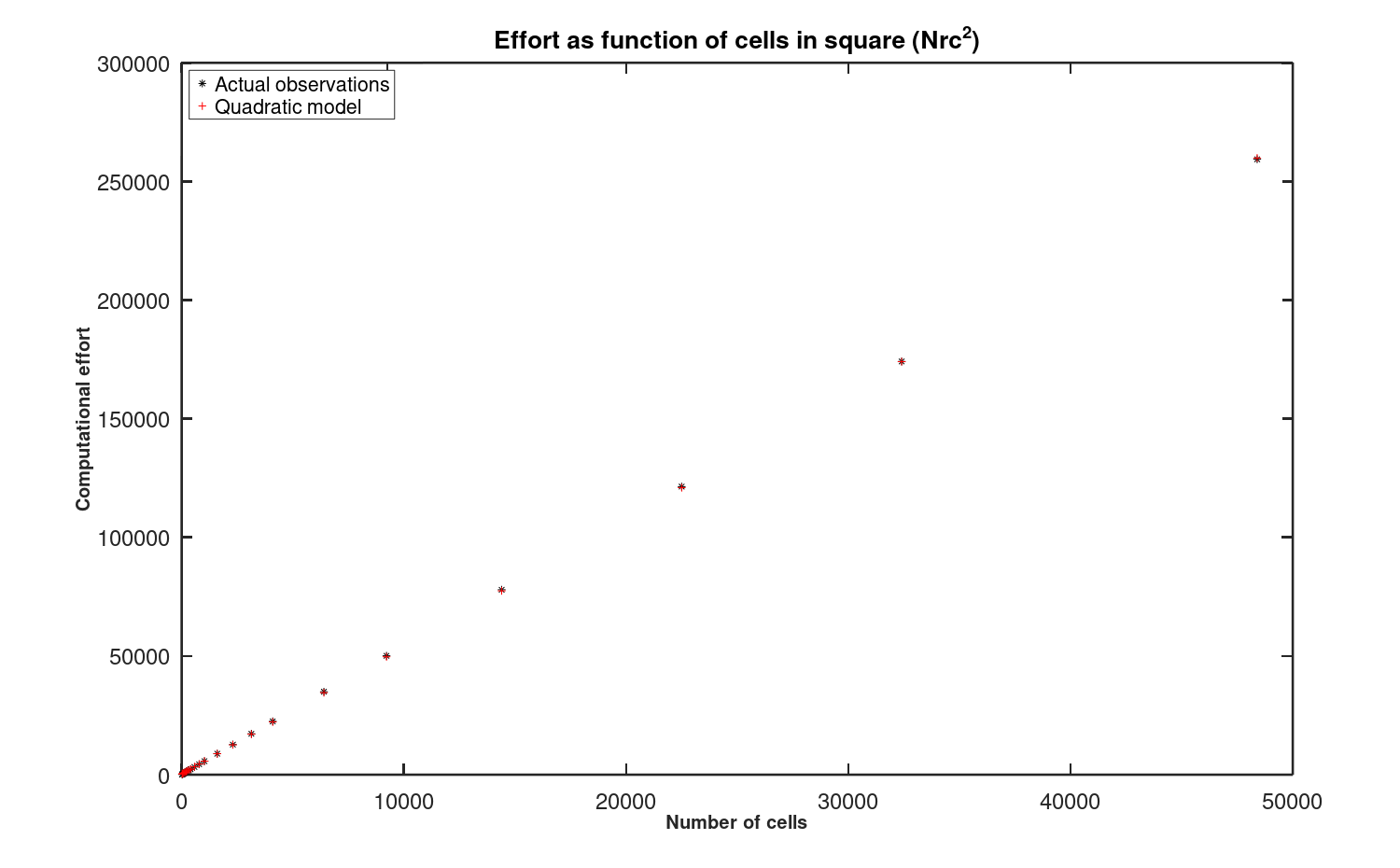
Figure 6: Effort per cell to modify storage contents.
The close correspondence between the model and the actual observations strongly indicates a growth rate proportional to the number of cells in the square — the effort is O(N2). Figure 7 shows that there is a relatively constant number of applied memory operations per cell to produce any Latin Square size, roughly 5 to 6 operations per cell.
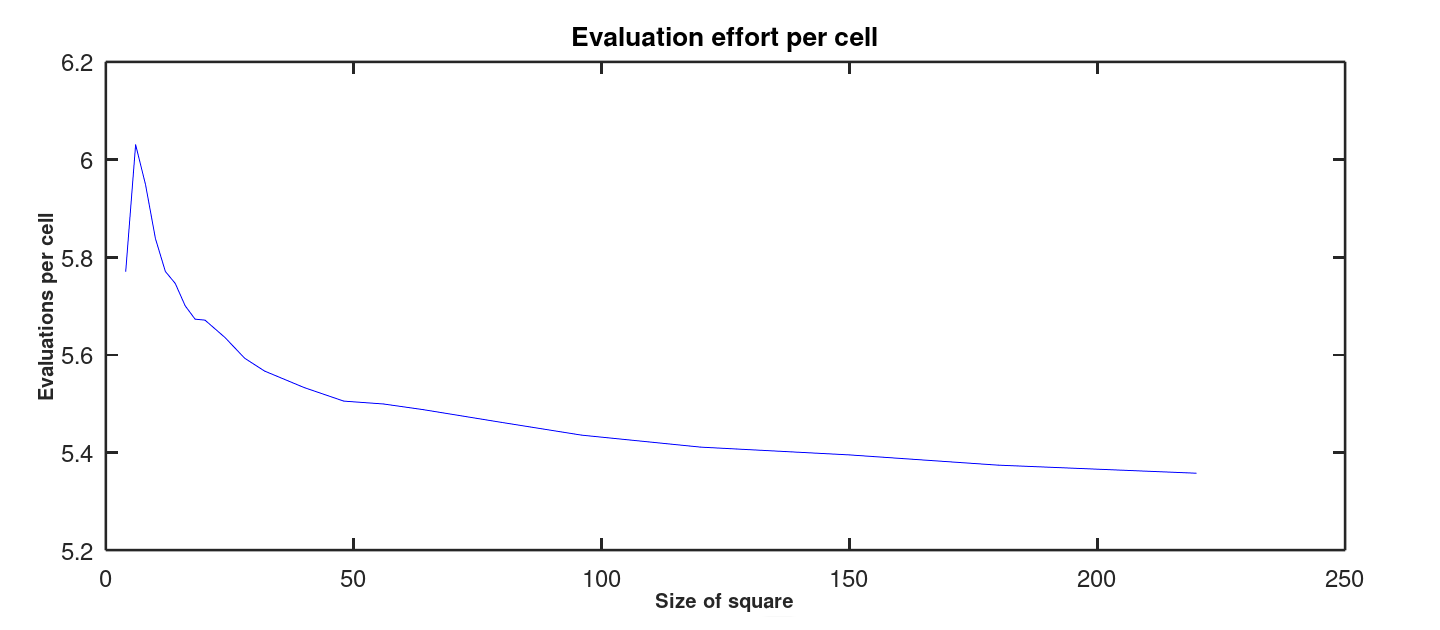
Figure 7: Computing effort per modified cell.
As an additional check, the quadratic model constructed from the smaller Latin Squares is used to extrapolate to significantly larger squares. Those predictions are then checked by generating and testing some larger squares. The results are illustrated in Figure 8. The points on the right half of the plot are the projections.
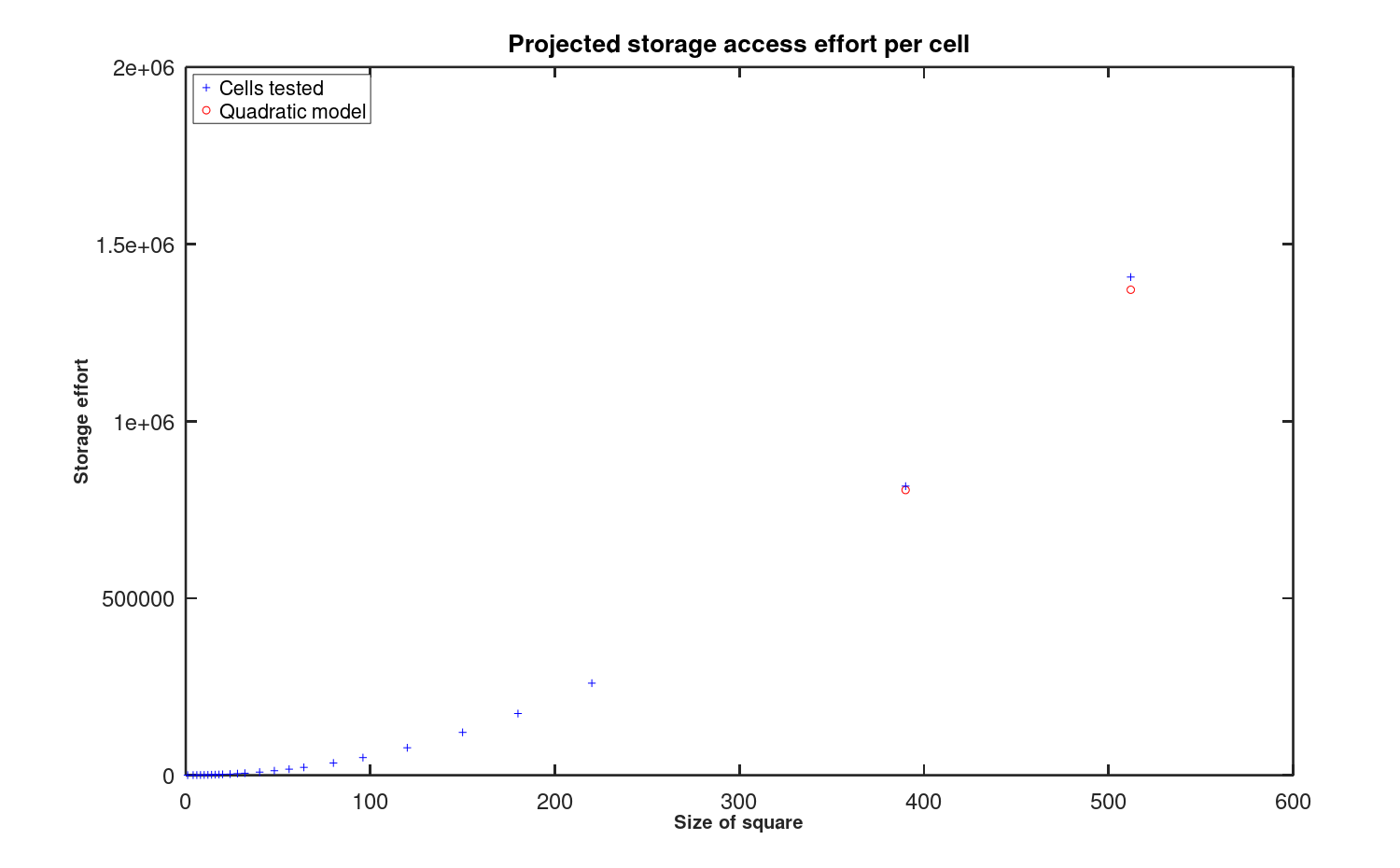
Figure 8: Exploratory extrapolation of quadratic complexity model.
Given that "best fit" heuristic models built from statistical data are not expected to perform perfectly, the extrapolations give no clear indication of deficiency in the quadratic model.
Effort expended to search cell availability
Operations used to look for available storage cells require only index lookup operations of complexity O(1), but there can be lots of these. Issues raised by these secondary operations are:
-
When selecting an available cell to add to a cover, how many tests are required to locate a cell that is not in conflict with any previous assignments for the current cover?
-
When a conflict is detected, how many tests are likely to be applied before finding a location where a symbol-split resolution is possible?
-
When resolving a conflict by circuit tracing, how many steps are likely to be needed to find a column in which there is no conflict with the current symbol?
These behaviors, all governed by probabilities that change at every step, are very difficult to describe analytically. To examine them empirically, instrumentation is added to the Method of Covers algorithm to count the exploration steps that occur during Latin Square construction. Pools of 2000 randomly-generated Latin Squares of each size are tested. The results are illustrated in Figure 9.
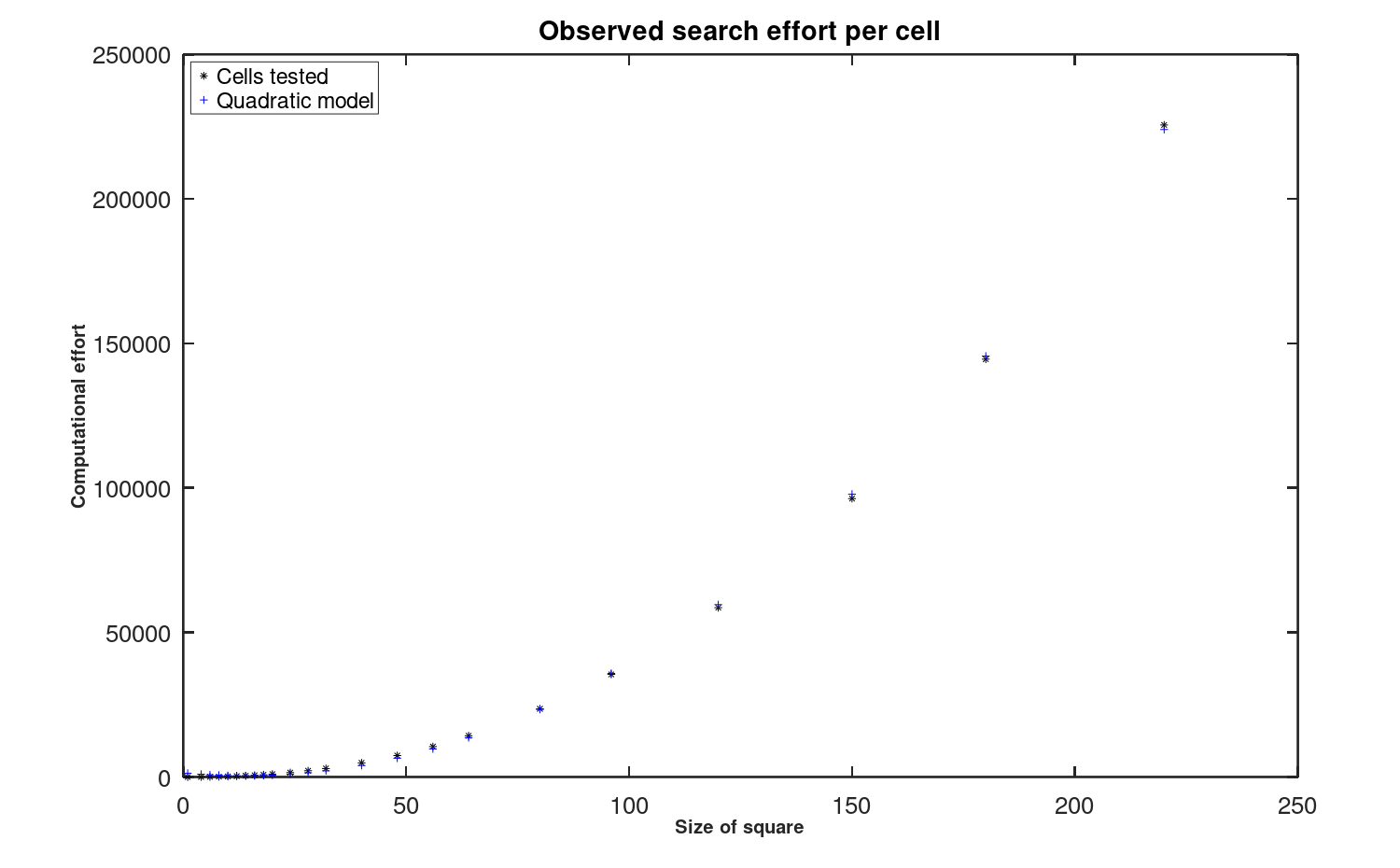
Figure 9: Effort expended for search operations
Once again, a quadratic model provides a near-perfect description of the number of search operations required. Comparing the y-axis labels on Figure 8 and Figure 9, we can observe that there there are roughly 7 times as many memory-modifying operations as exploratory ones.
However, there is a reason not to trust this quadratic model. Side effects were expected from the simplifications made to the circuit alternation resolution processing for the sake of computing efficiency. As for the case for studying the memory access effort, the quadratic model for exploratory effort is used to generate predictions for that effort in constructing larger Latin Squares. Figure 10 compares these predictions to actual performance.
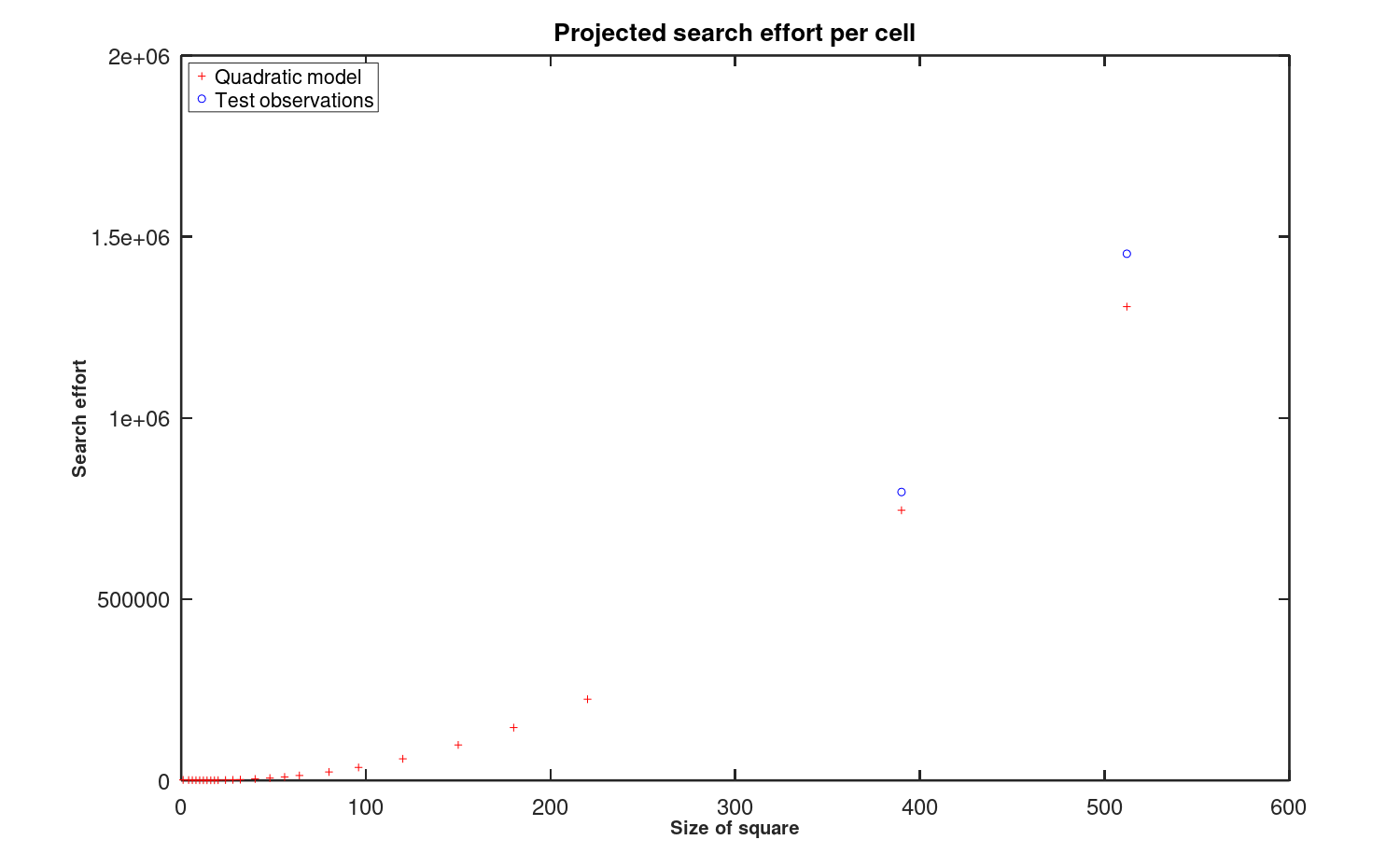
Figure 10: Extrapolation fails with O(N2) search effort model
The growth projected by the O(N2) model used for Figure 10 is not providing accurate estimates when projected to larger Latin Squares.
Returning to the smaller Latin Squares, an alternative growth model is
proposed, assuming growth proportional to N2.2 rather
than N2. This change results in negligible
differences between the two models for any of the smaller Latin Square
sizes. However, the projections to larger Latin Square sizes are shown
in Figure 11.
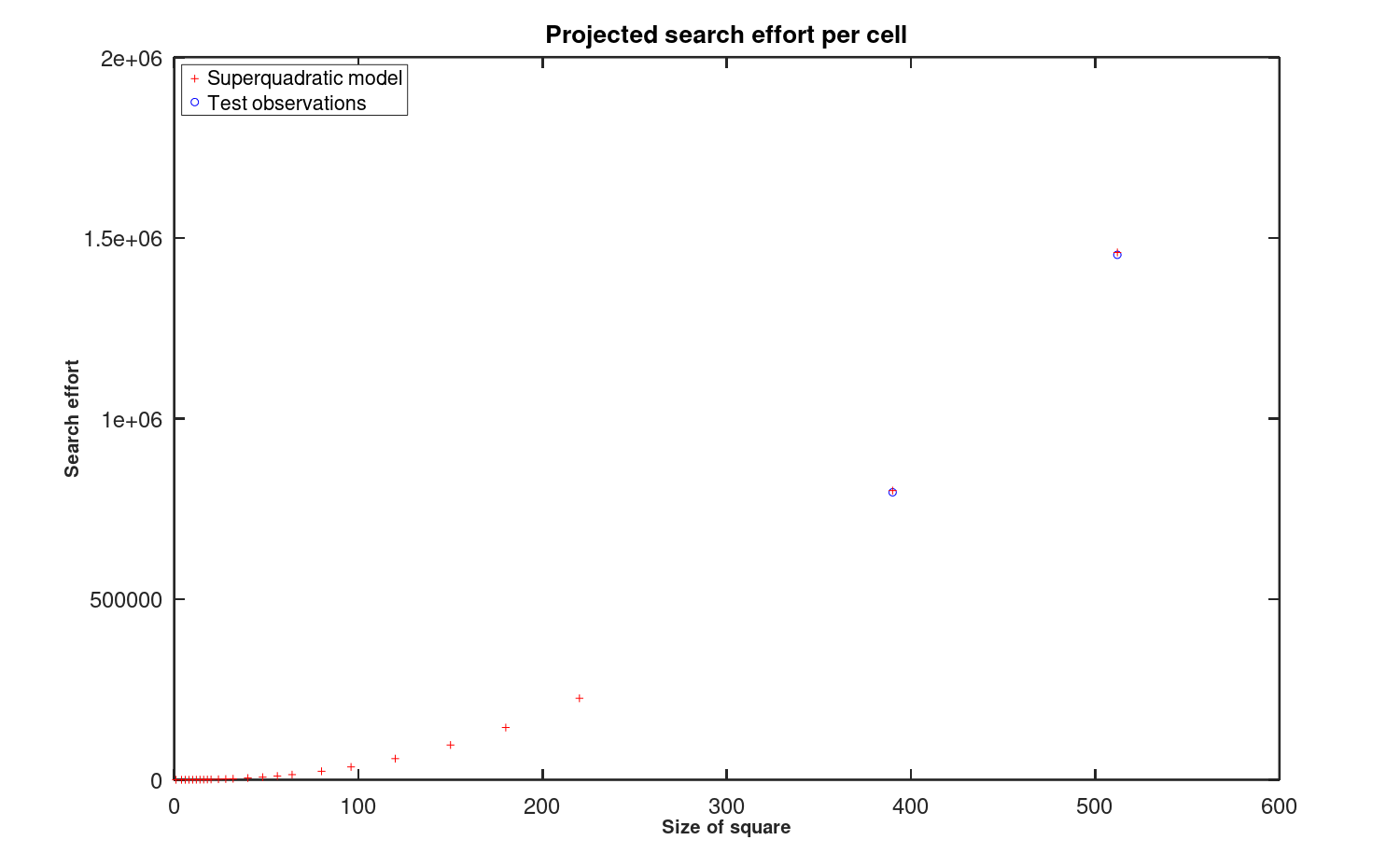
Figure 11: Extrapolated search effort using O(N2.2) growth model
The modified O(N2.2) growth model provides
a remarkably close prediction of the exploratory effort required to
construct the larger Latin Squares. Though that effort starts small, it
will grow disproportionately and start to dominate the total effort as N
grows very large. Consequently, the Method of Covers (using the simplified
resolution heuristic) must be considered to be approximately
O(N2.2), not O(N2). It is estimated that for
sizes near N=17000 the effort expended for performing search operations
will become roughly equal to the effort expended for memory storage
operations.
Conclusions
The Method of Covers shows significant promise as a general purpose replacement for the Jacobson-Matthews scrambler algorithm that has been widely used since its publication in 1996. The Method of Covers is valid for producing Latin Squares as small as N=1. Bias properties are not perfect, but compare well with the established algorithm. No artificial "starting pattern" Latin Square is required, which saves at least N2 initialization operations, and eliminates the need for row-column permutations to break up initial pattern correlations, saving another 4 N2 memory access operations. Complexity is empirically observed to be approximately O(N2.2), but is almost indistinguishable from an O(N2) model when the Latin Square sizes are limited to under N=256. The Jacobson-Matthews method was described as order O(N3). A good implementation of that algorithm combined with a reasonable stopping criterion reduces its complexity to O(N2) [7], but its per cell computational overhead is very high. The Method of Covers, which requires a little more total computational effort than the Jacobson-Matthews algorithm requires for its initialization, will be faster in all practical situations given implementations of comparable quality. The biggest drawback for the Method of Covers is the requirement for the relatively large 5·N2 storage locations — perhaps not a major point of concern with modern processors.
The Method of Covers appears to be ready for careful field testing and practical application. A model implementation in the python language is available for study and further development under an open source license. [11]
References:
[1] Colbourn, C. J.; "The complexity of completing partial Latin squares" Discrete Applied Mathematics 8(1) (1984), 25–30.
[2] Kuhl J, Schroeder M.W.; "Completing partial Latin squares with one nonempty row, column, and symbol", The Electronic Journal of Combinatorics 23(2) (2016), #P2.23
[3] DeSalvo, Stephen; "Exact sampling algorithms for Latin squares and Sudoku matrices via probabilistic divide-and-conquer" (2016), arXiv:1502.00235.
[4] McKay, Brendan; Wanless, Ian ; "On the number of Latin squares", Department of Computer Science, Australian National University, Canberra, Australia (2009)
[5] Jacobson, M. T.; Matthews, P. "Generating uniformly distributed random Latin squares"; Journal of Combinatorial Designs 4 (6)" (1996), pp 405–437 .
[6] Trammell, Larry; "Screening Test for Latin Square Randomness using Matchings" (2025, unpublished). A draft is available at //www.ridgerat-tech.us/latinsq/bias/BiasTesting.html .
[7] Trammell, Larry; "A Better Jacobson-Matthews Latin Square Shuffler" (2023, unpublished). A draft is available at //www.ridgerat-tech.us/latinsq/jmmethod/JMMethod.html .
[8] Gyárfás, András; Sárközy, Gábor N.; "Rainbow matchings and cycle-free partial transversals of Latin squares"; Discrete Mathematics 327 (2014), 96–102.
[9] Hierholzer, Carl; Chr. Wiener (1873). "Ueber die Möglichkeit, einen Linienzug ohne Wiederholung und ohne Unterbrechung zu umfahren"; Mathematische Annalen" (1873) Ch 6 pp. 30–32.
[10] Wanless, Ian; (1873). "Transversals in Latin Squares"; Quasigroups and Related Systems 15 (2007), 11 − 33.
[11] Trammell, Larry, implementation in Python distributed under an open source Creative Commons CC-BY License. You can download a copy from rlsmoc.py.
This page and its contents are licensed under a Creative Commons Attribution 4.0 International License. For complete information about the terms of this license, see http://creativecommons.org/licenses/by/4.0/. The license allows copying, usage, and derivative works for individual or commercial purposes under few restrictions.
Document history:
Version 1.0 draft prepared in HTML format by Larry Trammell, copyright holder, who released the document irrevocably 2026-06-04 under the terms of the CC-BY-4.0 license.